

1. 索引工具
索引(Concordance)是呈现检索项和其共现语境的一种方式。检索项由词或短语以及词性赋码标记、通配符(wildcard)和正则表达式(regular expression)等构成。索引行可以按各种条件排序,常见的方法是按中心词左边或右边第N个词的字母顺序排序。研究者可对索引行数据做进一步分析,如搭配、类连接等,发现语言中反复出现的现象,从而揭示人们使用语言的模式(pattern)。
1.1 BFSU索引工具简介
BFSU CQPweb在线检索平台
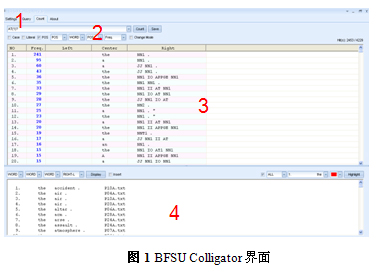
1.2 BFSU Colligator用法示例(图1)
(1)菜单提供以下功能:
设置(Setting):选择文本,设定跨距,指定单词和赋码标记间的分隔符。
检索(Query):检索语言特征,
统计(Count):统计类连接的种类和频数。
(2)用户在此输入检索式。检索式支持正则表达式,如检索冠词的表达式为:AT(1)?。
(3)显示类连接中的中心词和与其共现词类的种类和频率。
(4)点击区域3中的某一类连接种类后,在此显示其中的具体词项。
 |
2. 标注工具
标注是给语料库增添信息的过程,McEnery & Hardie(2012:29-31)认为可以把这些信息分为三类:
(1)元信息(Metadata)。如书面语中的文本类型(新闻、小说等);口语中说活人的特征(性别、年龄等)。
(2)文本信息(Textual Mark-up)。如书面语中的段落、句子;口语中的停顿、重复等。
(3)语言学信息(Linguistic Annotation)。如单词的词性、句子的结构和功能等。
研究者根据上述三种标注类型可以从语料库中提取相应的信息开展研究,如女性和男性在口语中使用形容词的异同。
2.1 BFSU标注工具简介
Metadata Encoder:元信息标注工具。可以在书面语语料库中添加文本作者、作者国籍和出版年代等信息;在口语语料库中添加说活人性别、年龄和社会地位等信息。用户可以在Metadata Encoder的配置文件中自行添加元信息的类别如<sex>、<age>等,然后在软件中针对每个类别进行标注,添加的信息会以下列格式保存在文本文件中:
<sex>female</sex>
<age>22</age>
研究者可以根据文本中的元信息从语料库中提取某一类型的文本(如年龄在18-25之间的女性话语),建立子语料库(参看下面 Sub-corpus Creator的介绍)开展研究。
TreeTagger for Windows 2.0:TreeTagger是德国斯图加特大学Helmut Schmid开发的一款自动词性标注软件,采用宾州树库符码集(http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/Penn-Treebank-Tagset.pdf)。TreeTagger for Windows 2.0是其图形界面,支持英语、德语、法语、意大利语等四种语言的词性标注,同时还支持词形还原(lemmatization)功能。下面是该软件对句子“The cuisine of Xinjiang reflects the region's many ethnic groups and refers particularly to Uyghur cuisine.”的标注结果(用户可与下文BFSU Stanford POS Tagger的标注结果相比较发现两者符码的异同):The_DT cuisine_NN of_IN Xinjiang_NP reflects_VVZ the_DT region_NN 's_POS many_JJ ethnic_JJ groups_NNS and_CC refers_VVZ particularly_RB to_TO Uyghur_NP cuisine_NN ._SENT
BFSU Stanford POS Tagger 1.0:Stanford POS Tagger是斯坦福大学自然语言处理小组开发的一款词性自动标注软件,采用宾州树库符码集(Marcus等:1993),符码准确率可达到96.97%(http://nlp.stanford.edu/software/pos-tagger-faq.shtml)。BFSU Stanford POS Tagger是其图形界面,它降低了原软件的操作难度,用户无需在命令行中输入命令和参数就可对文本进行符码。运行该软件前需安装JAVA虚拟机(http://www.java.com/en/download/)。下面是该软件对句子“The cuisine of Xinjiang reflects the region's many ethnic groups and refers particularly to Uyghur cuisine.”的标注结果(用户可与上文TreeTagger for Windows的标注结果相比较发现两者符码的异同):The_DT cuisine_NN of_IN Xinjiang_NNP reflects_VBZ the_DT region_NN 's_POS many_JJ ethnic_JJ groups_NNS and_CC refers_VBZ particularly_RB to_TO Uyghur_NNP cuisine_NN ._.
BFSU Stanford Parser 1.0:Stanford Parser是斯坦福大学自然语言处理小组开发的一款句法自动切分软件,可以切分句子的短语结构(Phrase Structure)和依存关系(Dependency Relation)。BFSU Stanford Parser 1.0是其图形界面,它降低了原软件的操作难度,用户无需在命令行中输入命令和参数就可对文本进行句法切分。利用该软件对句子“The cuisine of Xinjiang reflects the region's many ethnic groups and refers particularly to Uyghur cuisine.”进行句法切分后可以输出以下两种格式:
(1)括号格式的短语结构。其中NP、VP和PP分别代表名称短语、动词短语和介词短语:(ROOT
(S
(NP
(NP (DT The) (NN cuisine))
(PP (IN of)
(NP (NNP Xinjiang))))
(VP
(VP (VBZ reflects)
(NP
(NP (DT the) (NN region) (POS 's))
(JJ many) (JJ ethnic) (NNS groups)))
(CC and)
(VP (VBZ refers)
(ADVP (RB particularly))
(PP (TO to)
(NP (NNP Uyghur) (NN cuisine)))))
(. .)))
(2)依存关系。其中det表示限定词与名词之间的关系;nsubj表示句子主语与谓语间的关系。其它依存关系可参考de Marneffe & Manning(2008):
det(cuisine-2, The-1)
BFSU Qualitative Coder 1.0 & BFSU Qualitative Explorer:在语法、语义和语用等层面的许多语言现象无法通过软件自动标注,如对话中言语行为(dialogue act)的种类(请求、疑问赞同等)、小说中人物话语和思想的呈现方式(直接应用、间接应用等)以及与某一语言特征如情态动词共现的其它语言特征,如主语的生命度(有灵、无灵主语),后续实义动词的语义种类(状态、过程动词等)、所在句子的类型(陈述句、疑问句等),都需要手工进行标注。研究者可以利用BFSU Qualitative Coder自行设定语言现象的种类,在文本中进行手工标注。标注完成后可以用BFSU Qualitative Explorer统计各种语言现象出现的频率。
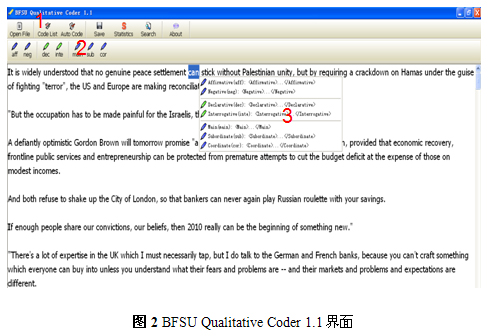
2.2 BFSU Qualitative Coder 1.0用法示例(图2)
(1)选择待标注文件和包含标注类别的文件(Code List)。
(2)标注类别列表。如本例中标注情态动词can所在句子的三种句法特征(Deshors 2010:114-115):肯定(aff)/否定(neg)、陈述(dec)/疑问(inte)以及主句(main)/从句(sub)/并列句(cor)。
(3)选择待标注项后,点击鼠标右键出现标注快捷菜单。
 |
3. 文本处理工具
3.1 BFSU文本处理工具简介
BFSU Sentence Segmenter 1.0:我们通常以逗号、句号、问号和感叹号等标点符号作为英文句子间的分界点,但如果采取上述方法进行自动分句的话会将一些缩略词的词尾(如Dr.、Mrs.、Ph.等)误判为句子结尾,造成切分错误。BFSU Sentence Segmenter支持用户自定义缩略词表,可以通过扩充缩略词表提高句子切分的准确率。
Sub-corpus Creator:该软件利用语料库中的文本名称以及文本中的元信息建立研究者所需的子语料库。如CROWN语料库中以A、B、C开头的文件代表新闻语体,研究者可以用(A|B|C)\S+\.txt这一正则表达式选定这类文本。同时该软件还可以选择文本内容,如研究介绍中国的新闻报道可以在文本内容中输入表达式china|chinese。
Readability Analyzer 1.0:通过对文本平均词长、平均句长、形符/类符比等特征的统计计算英文文本的易读性。
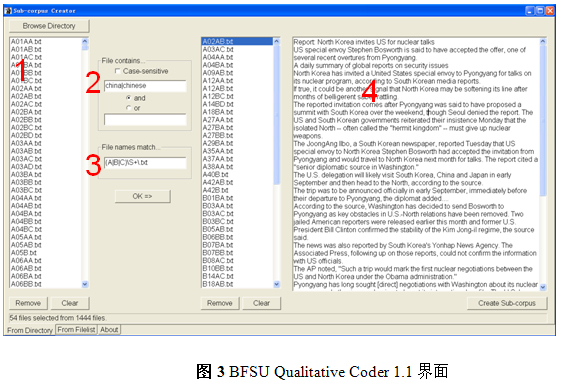
3.2 Sub-corpus Creator用法示例(图3):
(1)选择语料所在文件夹
(2)输入检索项和文件名
(3)用正则表达式过滤文件名
(4)符合检索条件的文本
 |
4. 数据驱动学习工具
数据驱动学习(Data-driven Learning)是指老师和学生通过检索语料库、分析索引行的方法教授/学习二语/外语的过程。这一方法强调学生的主动性,鼓励他们通过“发现式”的学习方法归纳语言在真实语境下的使用规律。
4.1 BFSU数据驱动学习工具简介
BFSU Sentence Collector 1.0:用于英语教学的索引工具,内置大学英语教材语料库(http://www.corpus4u.org/forum/showthread.php?t=3217)与四级词表。与上文介绍的索引工具不同的是其呈现方式为含有检索词的整句;另外用户可以根据句子长度和句子中的新词数(未出现在四级词表中的单词)来筛选例句。该工具支持正则表达式检索,如输入as \S+ as可以检索出含有as well as、as much as等短语的例句。
BFSU NewWord Marker 1.0:新词标记工具。根据用户指定的基准词表(如四、六级词表)输出特定文本中含有新词的句子,每句后列出未出现于词表中的新词以及该句所在的文件名称。进行新词标记前用户可以用BFSU Sentence Segmenter 1.0先对文本进行分句处理。
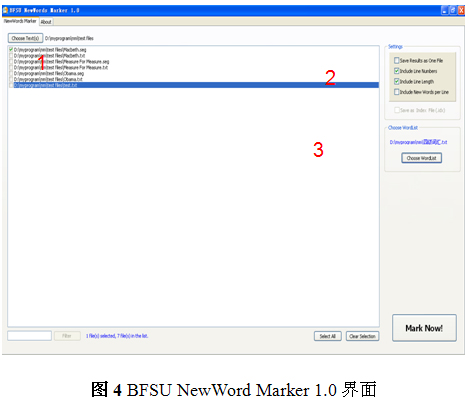
4.2 BFSU NewWord Marker 1.0用法示例(图4):
(1)选择待标记文本。
(2)设置输出格式。如句子序号、长度以及每句中新词个数等。
(3)选择基准词表。
 |
5. 其它
5.1 BFSU 其他语料库工具简介
Chi-square and Log-likelihood Calculator:语料库语言学中涉及许多对比研究,在这种研究中研究者需要解答的一个问题是某种语言特征在不同样本(语料库)间的频率差异是源于总体差异还是抽样误差造成的随机事件。要回答这一问题需要借助卡方检验或对数似然率检验,其基本原理可以通过表1说明。表1中F为语言特征, F代表不是F的语言特征;O代表观察频率,E为预期频率。
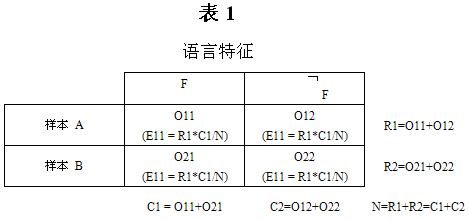 |
卡方检验的零假设为H0:P (语言特征F |总体 A) = P(语言特征F |总体 B),即语言特征F在样本A中所代表的语言总体中的比率与在样本B所代表的语言总体中的比率相等。如果零假设成立,那么观测频数和预期频数的检验统计量符合卡方分布。该检验统计量又称为卡方值,其计算公式为:
如果卡方值大于3.84,零假设成立的概率为95%以上。但是当表1中的预期频率小于5时,应该使用对数似然率来减少误差,对数似然率的计算公式为(Dunning 1993):
对数似然率的临界值与卡方值一样均为3.84。
使用Chi-square and Log-likelihood Calculator时,用户只需输入表1中的O11、O12、R1、R2四个值即可很方便地计算出卡方值和对数似然率。
Log-likelihood Ratio Calculator:计算对数似然率的Excel版本,同Chi-square and Log-likelihood Calculator一样需要输入四个数值,输出结果中的“+”号意为某种语言特征在Corpus1比在Corpus2中使用的多,“-”号反之。
Chi-square and Log-likelihood Calculator
PatternBuilder 1.0:自动生成正则表达式的工具,帮助用户从词性符码语料库中提取各种语言特征。该工具可以生成简单的表达式如方位名词(\S+_NNL2\s)或较复杂的结构的表达式如被动语态(\S+_VB\w*\s(\S+_[RX]\w+\s)*\S+_V\wN\s),用户可以测试并保存自己编写的表达式。具体用法可参看梁茂成 (2009)。
Wordlist Tools 1.0:制作词表工具。用户可以按各种条件对词表进行筛选和重组:如通过与基准词表对比生成包含或不包含基准词表中单词的新的词表;按同一词族(word family)归并词表等。所有词表都包含单词频率、覆盖率(Range)以及其在各文本中的分布情况。
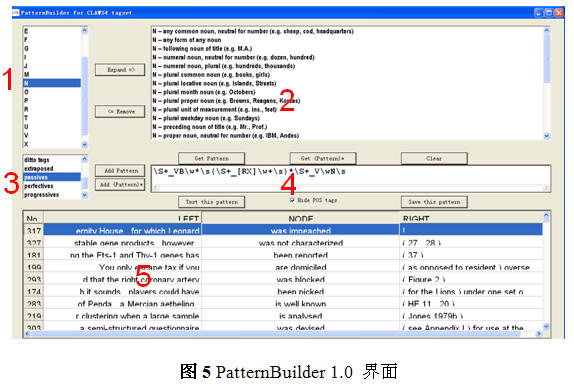
5.2 PatternBuilder 1.0用法示例(图5):
(1)显示赋码首字母,如名词以N开头、动词以V开头。
(2)包含特定赋码首字母的各种语言特征。
(3)用户自定义的各种语言特征,如被动语态等。
(4)显示所选语言特征的正则表达式,用户也可在此编辑表达式。
(5)按正则表达式检索语料库后的索引行,用以验证表达式的正误。
 |
我要提意见
版权所有 © 2006-2024 外语教学与研究出版社 高等英语教学网  京公网安备:11010802020459号 京ICP备11010362号-34
京公网安备:11010802020459号 京ICP备11010362号-34
